前言
前言:网上的参考链接:https://luzhijun.github.io/2017/12/10/pyspark%E4%BE%9D%E8%B5%96%E9%83%A8%E7%BD%B2/
下面开始详细步骤:
一. 开发机 由于集群是Linux系统,所以我们自己打包的Python环境最好也要在Linux环境下进行。
二. 下载Anaconda Anaconda是一个科学计算的Python发行版本,里面预安装了很多常用包,比如numpy、scipy、pandas、scikit-learn等,并提供了conda工具,很方便地管理第三方包,创建虚拟环境等。由于集群上的Python环境是2.7,所以应下载Anaconda2相关版本。
清华镜像下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda2-5.0.1-Linux-x86_64.sh
安装直接输入命令:bash Anaconda2-5.0.0.1-Linux-x86_64.sh ,基本就一直enter,最后会提示是否加入环境变量[yes/no]?,选择yes
conda工具使用教程:https://www.jianshu.com/p/d2e15200ee9b
如果安装成功,执行python出现下面的显示:
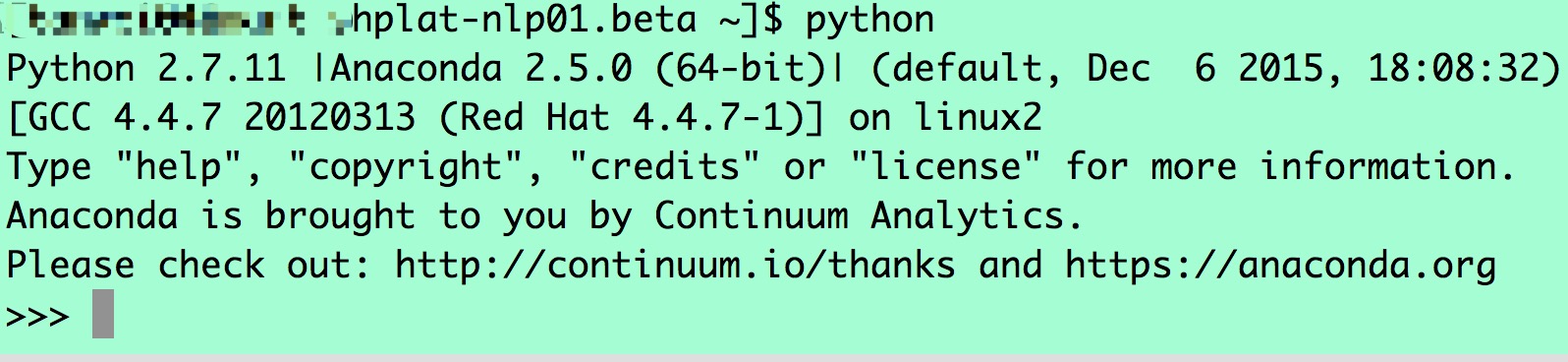
三. 利用conda创建虚拟环境 1.创建名为”dl_env”的python2虚拟环境
conda create -n dl_env python=2 (-n 指定给虚拟环境命名,python=2指定Python版本)

中间会提示是否继续,输入“y”,创建成功后,会出现以下界面:
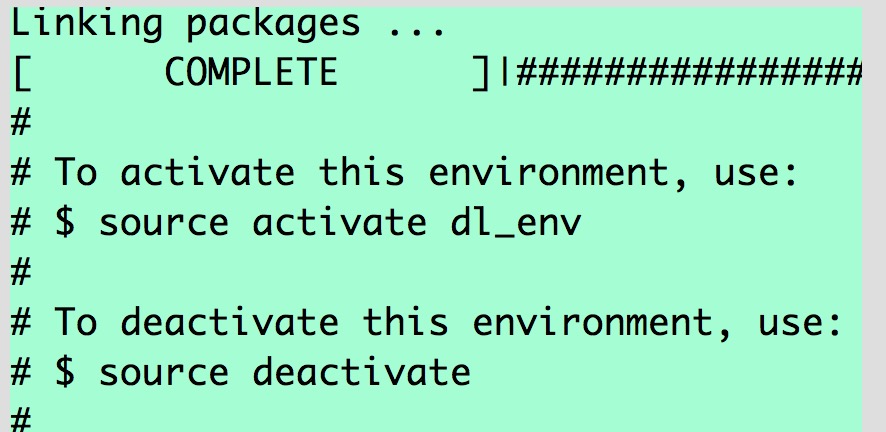
2.激活创建的环境
source activate dl_env

3.安装第三方包 同样可以使用pip或者conda安装自己想要的包:
pip install numpy -i https://pypi.douban.com/simple (-i 指定pip安装源,这里是豆瓣的源,公司的源是http://pypi.sankuai.com/simple/)
或者
conda install numpy

4.将虚拟环境打包 安装的所有虚拟环境都在anaconda2/envs文件夹下面,进入到该目录,将对于一个环境打包:
zip -r dl_env.zip dl_env
或者
1
tar -zcvf dl_env.tar dl_env/

5.通过hope将虚拟环境包上传到HDFS上
1
hope dfs -put ./dl_env.zip viewfs:///user/hadoop-shplat/nlp/xxx/ (指定自己的目录)

四. 在pyspark集群上使用自己的Python环境 如果使用hope,需要指定相关参数,给pyspark指定要用哪个Python环境,完整hope文件配置参考:
,主要将其中的dl_env换成 你自己的环境包名称
1
2
3
4
5
6
Shell
spark.yarn.appMasterEnv.PYSPARK_PYTHON = ./dl_env.zip/dl_env/bin/python
spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON = ./dl_env.zip/dl_env/bin/python
spark.yarn.appMasterEnv.LD_LIBRARY_PATH=/opt/rh/python27/root/usr/lib64
spark.executorEnv.LD_LIBRARY_PATH=/opt/rh/python27/root/usr/lib64
archives=viewfs:///user/hadoop-shplat/nlp/tanwei/dl_env.zip
完整的hope:
# 表示作业的类型,自动填充,请勿修改
[type]
type = pyspark
# 作业执行信息
[job_info]
# 表示作业执行时使用的hadoop账号,请修改为本组的hadoop账号,否则会报错
usergroup = hadoop-shplat
# 表示spark的版本信息,默认使用spark-1.6版本,spark-latest对应spark1.5
# 备选集合[spark-latest, spark-1.6, spark-2.1]
spark_version = spark-2.2
# 作业对应的主类名
main_py = main.py
# 执行作业必须的参数,提供默认配置,可以修改,不能删除
[env_args]
# 选择作业提交的队列
queue = root.rz.hadoop-shplat.data
#master = yarn-cluster
master = yarn
deploy-mode=cluster
driver-memory = 8G
executor-memory = 8G
executor-cores = 8
# 是否开启动态资源分配,默认开启
is_dynamic_allocation = true
# 开启动态资源分配后该参数表示最大executor数
num-executors = 8
# 执行作业非必须的参数,提供默认配置,可以修改,删除
[option_env_args]
# 作业运行次数,大于1代表会重试
spark.yarn.maxAppAttempts = 1
spark.yarn.appMasterEnv.PYSPARK_PYTHON = ./nlp_env.zip/nlp_env/bin/python
spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON = ./nlp_env.zip/nlp_env/bin/python
spark.yarn.appMasterEnv.LD_LIBRARY_PATH=/opt/rh/python27/root/usr/lib64
spark.executorEnv.LD_LIBRARY_PATH=/opt/rh/python27/root/usr/lib64
archives=viewfs:///user/hadoop-shplat/nlp/tanwei/nlp_env.zip
# spark.yarn.executor.memoryOverhead = 1024
# 作业参数,可以不填,在执行命令中指定
[args]
args =

